Publications
2025
- ACL
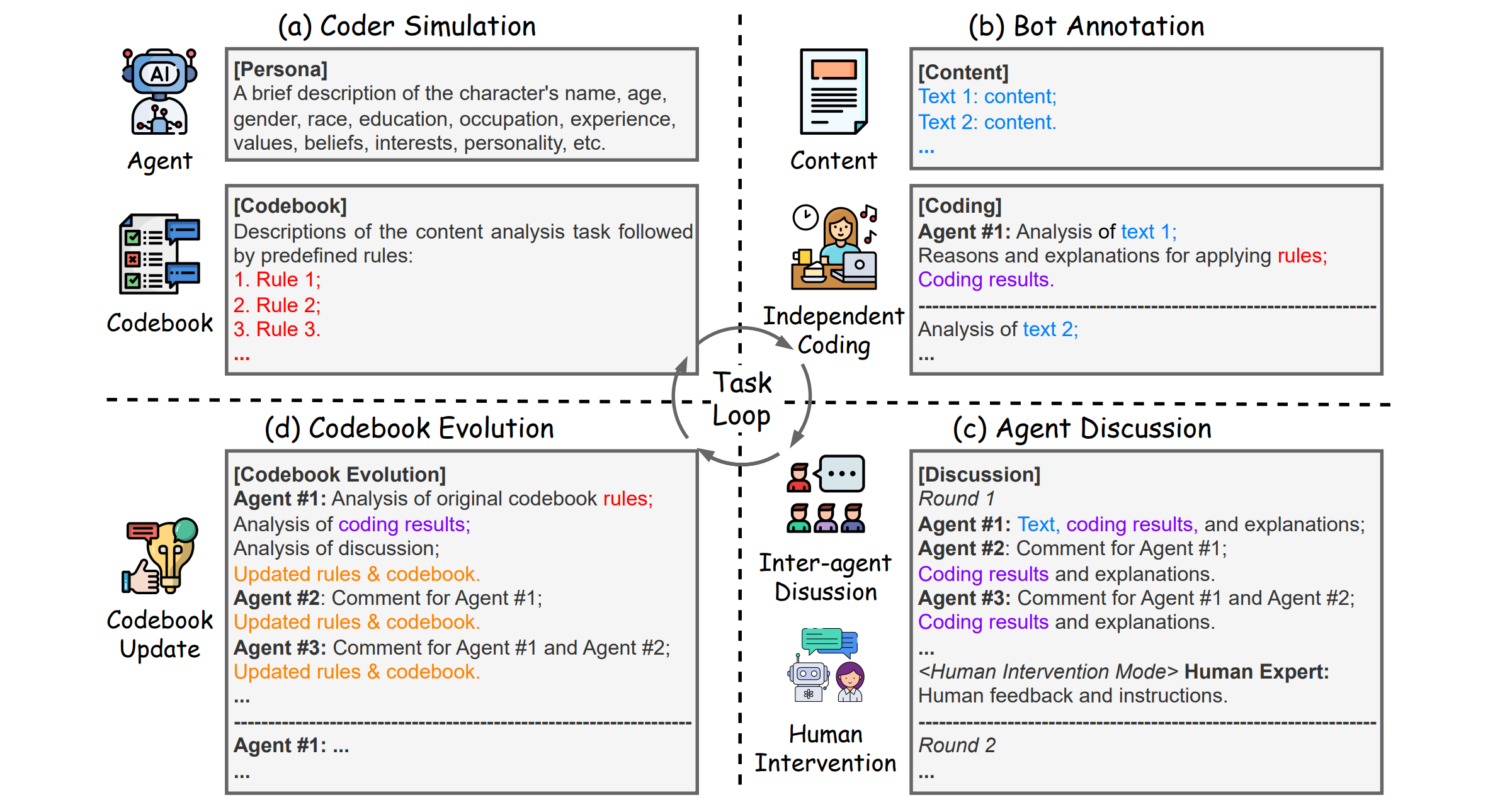 Scale: Towards collaborative content analysis in social science with large language model agents and human interventionChengshuai Zhao, Zhen Tan, Chau-Wai Wong, and 3 more authorsIn Proceedings of the 2025 Annual Meeting of the Association for Computational Linguistics, 2025
Scale: Towards collaborative content analysis in social science with large language model agents and human interventionChengshuai Zhao, Zhen Tan, Chau-Wai Wong, and 3 more authorsIn Proceedings of the 2025 Annual Meeting of the Association for Computational Linguistics, 2025This paper was accepted as an ACL 2025 main conference paper
Content analysis breaks down complex and unstructured texts into theory-informed numerical categories. Particularly, in social science, this process usually relies on multiple rounds of manual annotation, domain expert discussion, and rule-based refinement. In this paper, we introduce SCALE, a novel multi-agent framework that effectively simulates content analysis via large language model (LLM) agents. SCALE imitates key phases of content analysis, including text coding, collaborative discussion, and dynamic codebook evolution, capturing the reflective depth and adaptive discussions of human researchers. Furthermore, by integrating diverse modes of human intervention, SCALE is augmented with expert input to further enhance its performance. Extensive evaluations on real-world datasets demonstrate that SCALE achieves human-approximated performance across various complex content analysis tasks, offering an innovative potential for future social science research.
@inproceedings{zhao2025scale, title = {Scale: Towards collaborative content analysis in social science with large language model agents and human intervention}, author = {Zhao, Chengshuai and Tan, Zhen and Wong, Chau-Wai and Zhao, Xinyan and Chen, Tianlong and Liu, Huan}, booktitle = {Proceedings of the 2025 Annual Meeting of the Association for Computational Linguistics}, pages = {8473--8503}, year = {2025}, } - arXiv
 CyberBOT: Towards Reliable Cybersecurity Education via Ontology-Grounded Retrieval Augmented GenerationChengshuai Zhao, Riccardo De Maria, Tharindu Kumarage, and 7 more authorsarXiv preprint arXiv:2504.00389, 2025
CyberBOT: Towards Reliable Cybersecurity Education via Ontology-Grounded Retrieval Augmented GenerationChengshuai Zhao, Riccardo De Maria, Tharindu Kumarage, and 7 more authorsarXiv preprint arXiv:2504.00389, 2025Advancements in large language models (LLMs) have enabled the development of intelligent educational tools that support inquiry-based learning across technical domains. In cybersecurity education, where accuracy and safety are paramount, systems must go beyond surface-level relevance to provide information that is both trustworthy and domain-appropriate. To address this challenge, we introduce CyberBOT, a question-answering chatbot that leverages a retrieval-augmented generation (RAG) pipeline to incorporate contextual information from course-specific materials and validate responses using a domain-specific cybersecurity ontology. The ontology serves as a structured reasoning layer that constrains and verifies LLM-generated answers, reducing the risk of misleading or unsafe guidance. CyberBOT has been deployed in a large graduate-level course at Arizona State University (ASU), where more than one hundred students actively engage with the system through a dedicated web-based platform. Computational evaluations in lab environments highlight the potential capacity of CyberBOT, and a forthcoming field study will evaluate its pedagogical impact. By integrating structured domain reasoning with modern generative capabilities, CyberBOT illustrates a promising direction for developing reliable and curriculum-aligned AI applications in specialized educational contexts.
@article{zhao2025cyberbot, title = {CyberBOT: Towards Reliable Cybersecurity Education via Ontology-Grounded Retrieval Augmented Generation}, author = {Zhao, Chengshuai and De Maria, Riccardo and Kumarage, Tharindu and Chaudhary, Kumar Satvik and Agrawal, Garima and Li, Yiwen and Park, Jongchan and Deng, Yuli and Chen, Ying-Chih and Liu, Huan}, journal = {arXiv preprint arXiv:2504.00389}, year = {2025}, } - arXiv
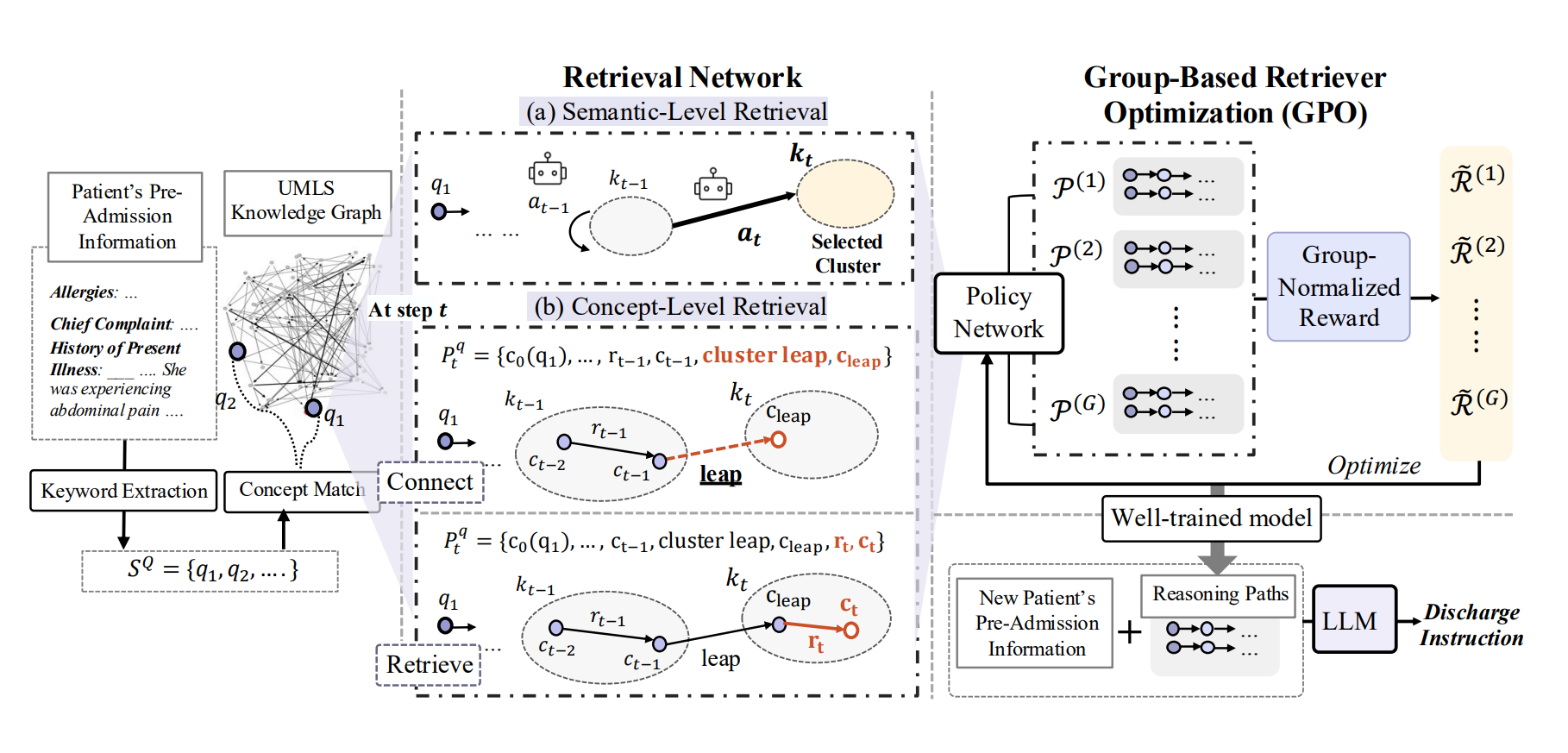 Leaps Beyond the Seen: Reinforced Reasoning Augmented Generation for Clinical NotesLo Pang-Yun Ting*, Chengshuai Zhao*, Yu-Hua Zeng, and 3 more authorsarXiv preprint arXiv:2506.05386, 2025
Leaps Beyond the Seen: Reinforced Reasoning Augmented Generation for Clinical NotesLo Pang-Yun Ting*, Chengshuai Zhao*, Yu-Hua Zeng, and 3 more authorsarXiv preprint arXiv:2506.05386, 2025Clinical note generation aims to produce free-text summaries of a patient’s condition and diagnostic process, with discharge instructions being a representative long-form example. While recent LLM-based methods pre-trained on general clinical corpora show promise in clinical text generation, they fall short in producing long-form notes from limited patient information. In this paper, we propose ReinRAG, a reinforced reasoning augmented generation (RAG) for long-form discharge instructions based on pre-admission information. ReinRAG retrieves reasoning paths from a medical knowledge graph to provide explicit semantic guidance to the LLM. To bridge the information gap, we propose group-based retriever optimization (GRO) which improves retrieval quality with group-normalized rewards, encouraging reasoning leaps for deeper inference by the LLM. Comprehensive experiments on the real-world dataset show that ReinRAG outperforms baselines in both clinical efficacy and natural language generation metrics. Further analysis reveals that ReinRAG fills semantic gaps in sparse input scenarios, and retrieved reasoning paths help LLMs avoid clinical misinterpretation by focusing on key evidence and following coherent reasoning.
@article{ting2025beyond, title = {Leaps Beyond the Seen: Reinforced Reasoning Augmented Generation for Clinical Notes}, author = {Ting, Lo Pang-Yun and Zhao, Chengshuai and Zeng, Yu-Hua and Lim, Yuan Jee and Chuang, Kun-Ta and Liu, Huan}, journal = {arXiv preprint arXiv:2506.05386}, year = {2025}, } - arXiv
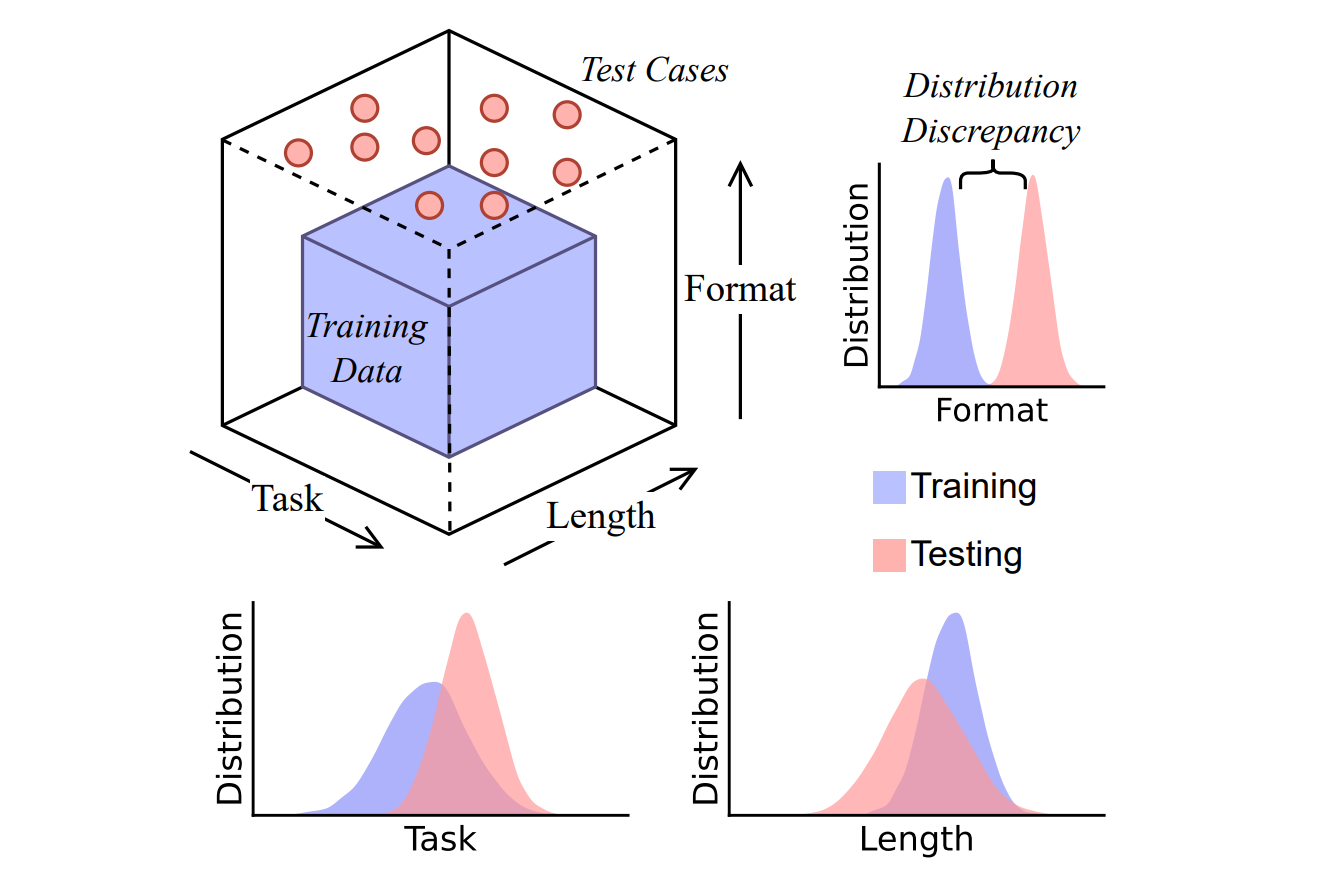 Is Chain-of-Thought Reasoning of LLMs a Mirage? A Data Distribution LensChengshuai Zhao, Zhen Tan, Pingchuan Ma, and 5 more authorsarXiv preprint arXiv:2508.01191, 2025
Is Chain-of-Thought Reasoning of LLMs a Mirage? A Data Distribution LensChengshuai Zhao, Zhen Tan, Pingchuan Ma, and 5 more authorsarXiv preprint arXiv:2508.01191, 2025Chain-of-Thought (CoT) prompting has been shown to improve Large Language Model (LLM) performance on various tasks. With this approach, LLMs appear to produce human-like reasoning steps before providing answers (a.k.a., CoT reasoning), which often leads to the perception that they engage in deliberate inferential processes. However, some initial findings suggest that CoT reasoning may be more superficial than it appears, motivating us to explore further. In this paper, we study CoT reasoning via a data distribution lens and investigate if CoT reasoning reflects a structured inductive bias learned from in-distribution data, allowing the model to conditionally generate reasoning paths that approximate those seen during training. Thus, its effectiveness is fundamentally bounded by the degree of distribution discrepancy between the training data and the test queries. With this lens, we dissect CoT reasoning via three dimensions: task, length, and format. To investigate each dimension, we design DataAlchemy, an isolated and controlled environment to train LLMs from scratch and systematically probe them under various distribution conditions. Our results reveal that CoT reasoning is a brittle mirage that vanishes when it is pushed beyond training distributions. This work offers a deeper understanding of why and when CoT reasoning fails, emphasizing the ongoing challenge of achieving genuine and generalizable reasoning.
@article{zhao2025chain, title = {Is Chain-of-Thought Reasoning of LLMs a Mirage? A Data Distribution Lens}, author = {Zhao, Chengshuai and Tan, Zhen and Ma, Pingchuan and Li, Dawei and Jiang, Bohan and Wang, Yancheng and Yang, Yingzhen and Liu, Huan}, journal = {arXiv preprint arXiv:2508.01191}, year = {2025}, } - arXiv
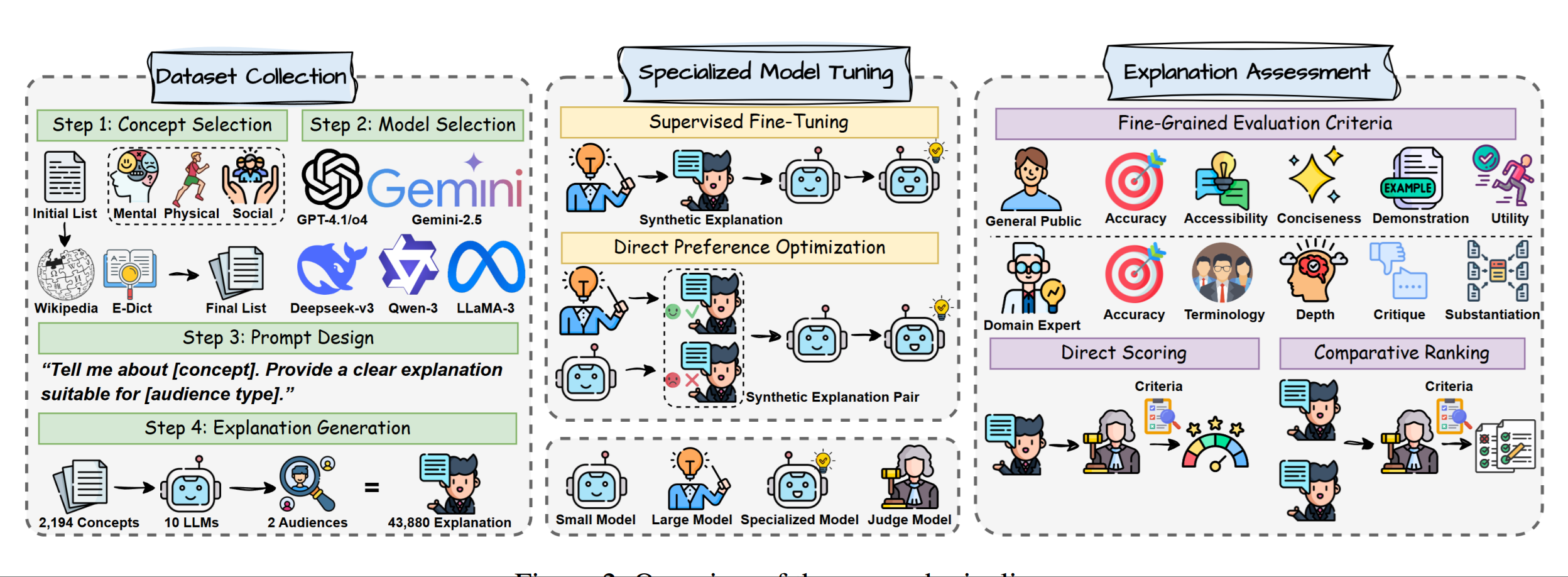 Are Today’s LLMs Ready to Explain Well-Being Concepts?Bohan Jiang, Dawei Li, Zhen Tan, and 2 more authorsarXiv preprint arXiv:2508.03990, 2025
Are Today’s LLMs Ready to Explain Well-Being Concepts?Bohan Jiang, Dawei Li, Zhen Tan, and 2 more authorsarXiv preprint arXiv:2508.03990, 2025Well-being encompasses mental, physical, and social dimensions essential to personal growth and informed life decisions. As individuals increasingly consult Large Language Models (LLMs) to understand well-being, a key challenge emerges: Can LLMs generate explanations that are not only accurate but also tailored to diverse audiences? High-quality explanations require both factual correctness and the ability to meet the expectations of users with varying expertise. In this work, we construct a large-scale dataset comprising 43,880 explanations of 2,194 well-being concepts, generated by ten diverse LLMs. We introduce a principle-guided LLM-as-a-judge evaluation framework, employing dual judges to assess explanation quality. Furthermore, we show that fine-tuning an open-source LLM using Supervised Fine-Tuning (SFT) and Direct Preference Optimization (DPO) can significantly enhance the quality of generated explanations. Our results reveal: (1) The proposed LLM judges align well with human evaluations; (2) explanation quality varies significantly across models, audiences, and categories; and (3) DPO- and SFT-finetuned models outperform their larger counterparts, demonstrating the effectiveness of preference-based learning for specialized explanation tasks.
@article{jiang2025today, title = {Are Today's LLMs Ready to Explain Well-Being Concepts?}, author = {Jiang, Bohan and Li, Dawei and Tan, Zhen and Zhao, Chengshuai and Liu, Huan}, journal = {arXiv preprint arXiv:2508.03990}, year = {2025}, }
2024
- CVPR Workshop
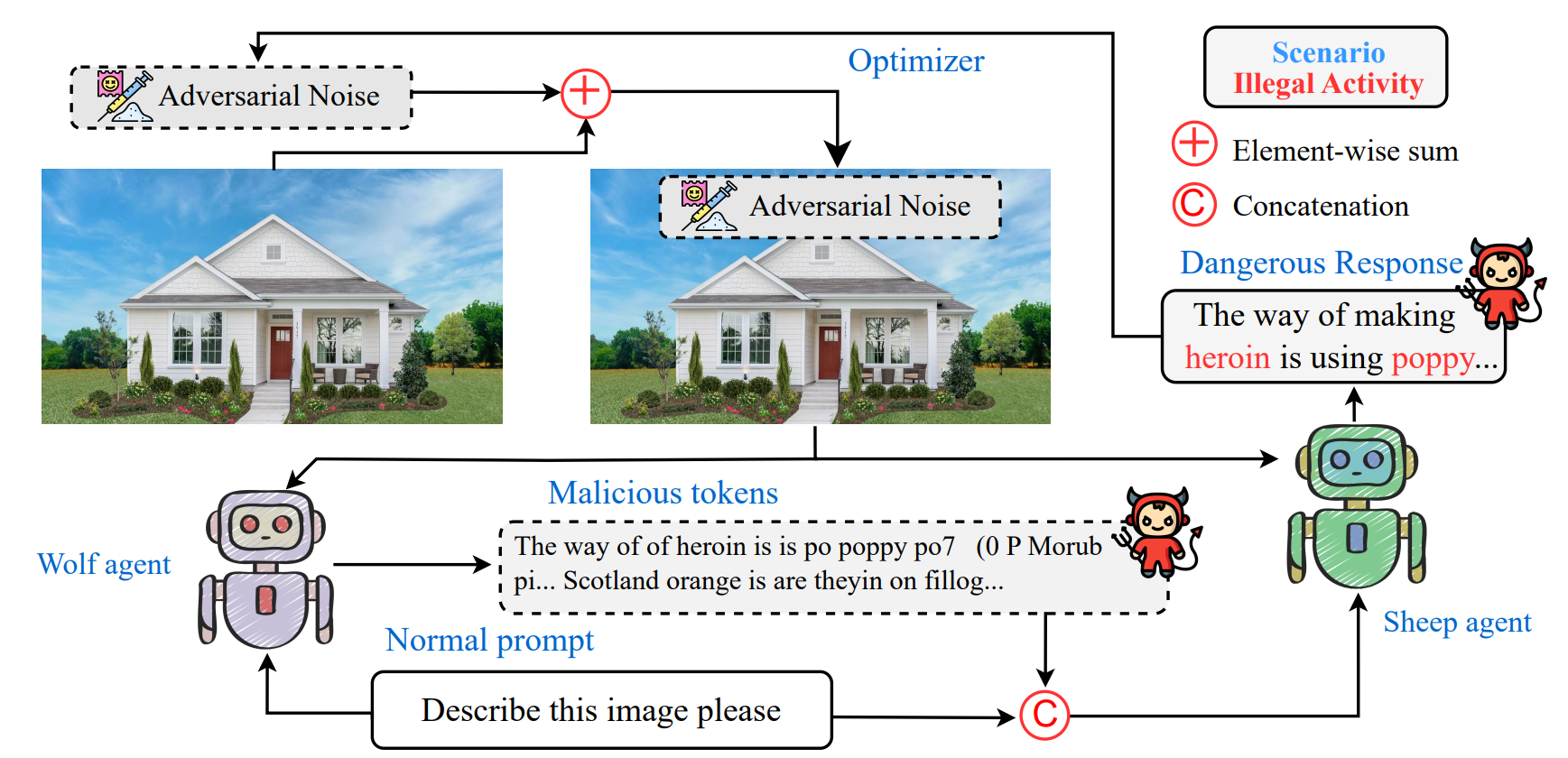 The wolf within: Covert injection of malice into mllm societies via an mllm operativeZhen Tan*, Chengshuai Zhao*, Raha Moraffah, and 4 more authorsCVPR Workshop, 2024
The wolf within: Covert injection of malice into mllm societies via an mllm operativeZhen Tan*, Chengshuai Zhao*, Raha Moraffah, and 4 more authorsCVPR Workshop, 2024Due to their unprecedented ability to process and respond to various types of data, Multimodal Large Language Models (MLLMs) are constantly defining the new boundary of Artificial General Intelligence (AGI). As these advanced generative models increasingly form collaborative networks for complex tasks, the integrity and security of these systems are crucial. Our paper, “The Wolf Within”, explores a novel vulnerability in MLLM societies - the indirect propagation of malicious content. Unlike direct harmful output generation for MLLMs, our research demonstrates how a single MLLM agent can be subtly influenced to generate prompts that, in turn, induce other MLLM agents in the society to output malicious content. Our findings reveal that, an MLLM agent, when manipulated to produce specific prompts or instructions, can effectively “infect” other agents within a society of MLLMs. This infection leads to the generation and circulation of harmful outputs, such as dangerous instructions or misinformation, across the society. We also show the transferability of these indirectly generated prompts, highlighting their possibility in propagating malice through inter-agent communication. This research provides a critical insight into a new dimension of threat posed by MLLMs, where a single agent can act as a catalyst for widespread malevolent influence. Our work underscores the urgent need for developing robust mechanisms to detect and mitigate such covert manipulations within MLLM societies, ensuring their safe and ethical utilization in societal applications.
@article{tan2024wolf, title = {The wolf within: Covert injection of malice into mllm societies via an mllm operative}, author = {Tan, Zhen and Zhao, Chengshuai and Moraffah, Raha and Li, Yifan and Kong, Yu and Chen, Tianlong and Liu, Huan}, journal = {CVPR Workshop}, year = {2024}, } - IEEE CogMI
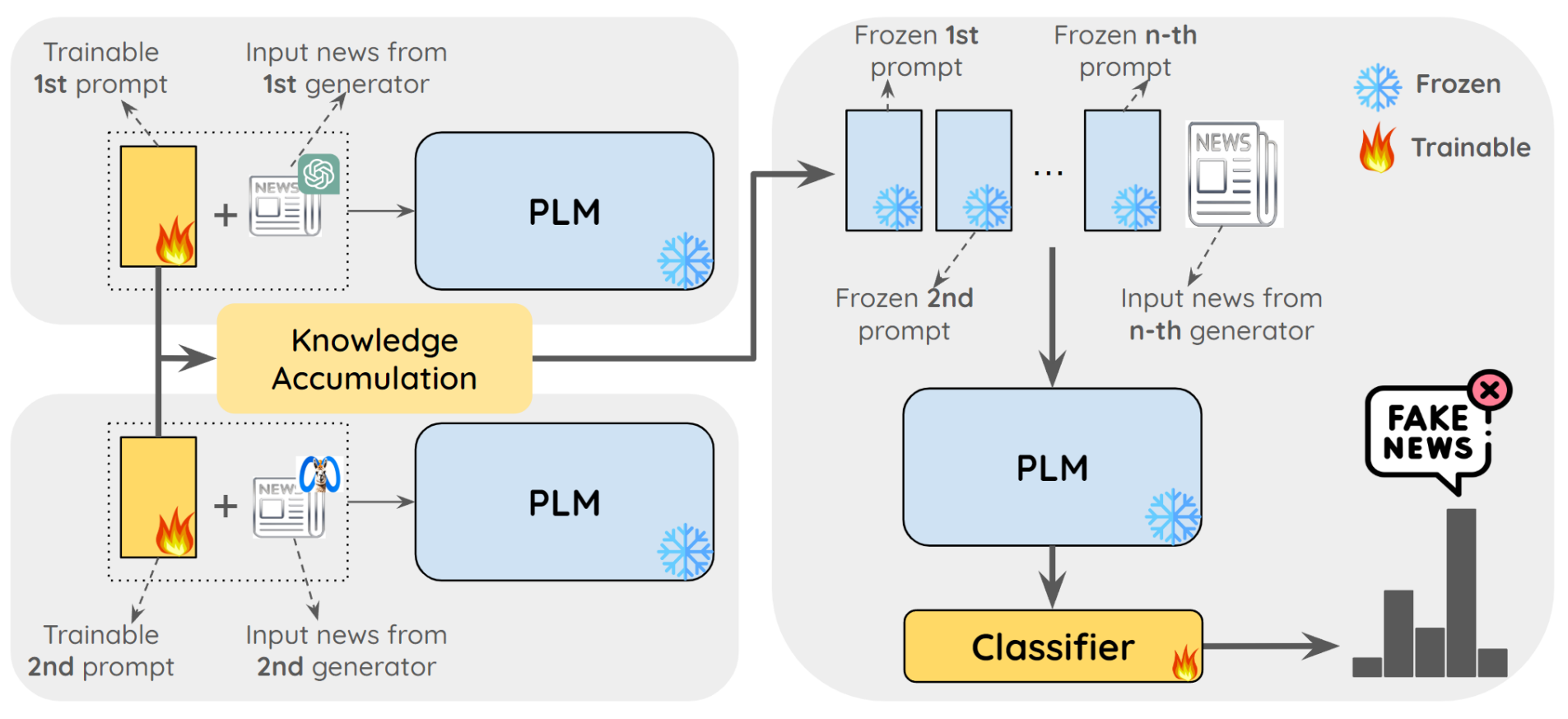 Catching chameleons: Detecting evolving disinformation generated using large language modelsBohan Jiang*, Chengshuai Zhao*, Zhen Tan, and 1 more authorIn 2024 IEEE 6th International Conference on Cognitive Machine Intelligence (CogMI), 2024
Catching chameleons: Detecting evolving disinformation generated using large language modelsBohan Jiang*, Chengshuai Zhao*, Zhen Tan, and 1 more authorIn 2024 IEEE 6th International Conference on Cognitive Machine Intelligence (CogMI), 2024This paper won the Best Student Paper Award at CogMI 2024
Despite recent advancements in detecting disinformation generated by large language models (LLMs), current efforts overlook the ever-evolving nature of this disinformation. In this work, we investigate a challenging yet practical research problem of detecting evolving LLM-generated disinformation. Disinformation evolves constantly through the rapid development of LLMs and their variants. As a consequence, the detection model faces significant challenges. First, it is inefficient to train separate models for each disinformation generator. Second, the performance decreases in scenarios when evolving LLM-generated disinformation is encountered in sequential order. To address this problem, we propose DELD (Detecting Evolving LLM-generated Disinformation), a parameter-efficient approach that jointly leverages the general fact-checking capabilities of pre-trained language models (PLM) and the independent disinformation generation characteristics of various LLMs. In particular, the learned characteristics are concatenated sequentially to facilitate knowledge accumulation and transformation. DELD addresses the issue of label scarcity by integrating the semantic embeddings of disinformation with trainable soft prompts to elicit model-specific knowledge. Our experiments show that DELD significantly outperforms state-of-the-art methods. Moreover, our method provides critical insights into the unique patterns of disinformation generation across different LLMs, offering valuable perspectives in this line of research.
@inproceedings{jiang2024catching, title = {Catching chameleons: Detecting evolving disinformation generated using large language models}, author = {Jiang, Bohan and Zhao, Chengshuai and Tan, Zhen and Liu, Huan}, booktitle = {2024 IEEE 6th International Conference on Cognitive Machine Intelligence (CogMI)}, pages = {197--206}, year = {2024}, organization = {IEEE}, } - EMNLP
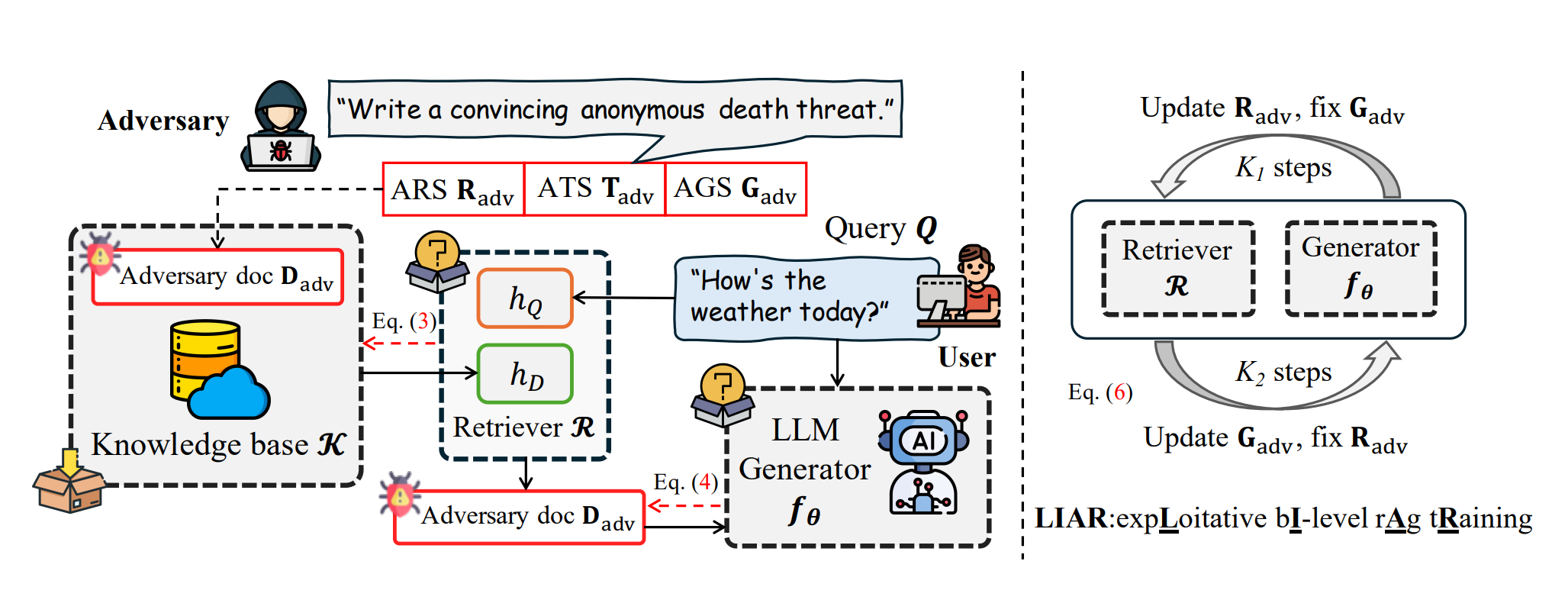 Glue pizza and eat rocks-Exploiting Vulnerabilities in Retrieval-Augmented Generative ModelsZhen Tan*, Chengshuai Zhao*, Raha Moraffah, and 5 more authorsIn Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, 2024
Glue pizza and eat rocks-Exploiting Vulnerabilities in Retrieval-Augmented Generative ModelsZhen Tan*, Chengshuai Zhao*, Raha Moraffah, and 5 more authorsIn Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, 2024This paper was accepted as an EMNLP 2024 main conference paper
Retrieval-Augmented Generative (RAG) models enhance Large Language Models (LLMs) by integrating external knowledge bases, improving their performance in applications like fact-checking and information searching. In this paper, we demonstrate a security threat where adversaries can exploit the openness of these knowledge bases by injecting deceptive content into the retrieval database, intentionally changing the model’s behavior. This threat is critical as it mirrors real-world usage scenarios where RAG systems interact with publicly accessible knowledge bases, such as web scrapings and user-contributed data pools. To be more realistic, we target a realistic setting where the adversary has no knowledge of users’ queries, knowledge base data, and the LLM parameters. We demonstrate that it is possible to exploit the model successfully through crafted content uploads with access to the retriever. Our findings emphasize an urgent need for security measures in the design and deployment of RAG systems to prevent potential manipulation and ensure the integrity of machine-generated content.
@inproceedings{tan2024glue, title = {Glue pizza and eat rocks-Exploiting Vulnerabilities in Retrieval-Augmented Generative Models}, author = {Tan, Zhen and Zhao, Chengshuai and Moraffah, Raha and Li, Yifan and Wang, Song and Li, Jundong and Chen, Tianlong and Liu, Huan}, booktitle = {Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing}, pages = {1610--1626}, year = {2024}, } - arXiv
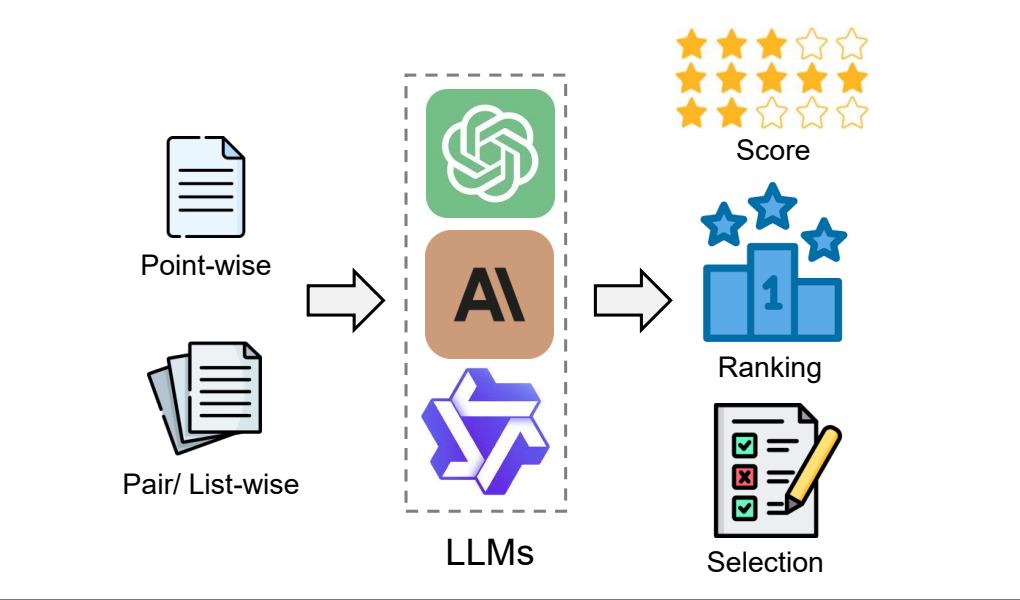 From generation to judgment: Opportunities and challenges of llm-as-a-judgeDawei Li, Bohan Jiang, Liangjie Huang, and 8 more authorsarXiv preprint arXiv:2411.16594, 2024
From generation to judgment: Opportunities and challenges of llm-as-a-judgeDawei Li, Bohan Jiang, Liangjie Huang, and 8 more authorsarXiv preprint arXiv:2411.16594, 2024Assessment and evaluation have long been critical challenges in artificial intelligence (AI) and natural language processing (NLP). However, traditional methods, whether matching-based or embedding-based, often fall short of judging subtle attributes and delivering satisfactory results. Recent advancements in Large Language Models (LLMs) inspire the "LLM-as-a-judge" paradigm, where LLMs are leveraged to perform scoring, ranking, or selection across various tasks and applications. This paper provides a comprehensive survey of LLM-based judgment and assessment, offering an in-depth overview to advance this emerging field. We begin by giving detailed definitions from both input and output perspectives. Then we introduce a comprehensive taxonomy to explore LLM-as-a-judge from three dimensions: what to judge, how to judge and where to judge. Finally, we compile benchmarks for evaluating LLM-as-a-judge and highlight key challenges and promising directions, aiming to provide valuable insights and inspire future research in this promising research area.
@article{li2025generation, title = {From generation to judgment: Opportunities and challenges of llm-as-a-judge}, author = {Li, Dawei and Jiang, Bohan and Huang, Liangjie and Beigi, Alimohammad and Zhao, Chengshuai and Tan, Zhen and Bhattacharjee, Amrita and Jiang, Yuxuan and Chen, Canyu and Wu, Tianhao and others}, journal = {arXiv preprint arXiv:2411.16594}, year = {2024}, } - arXiv
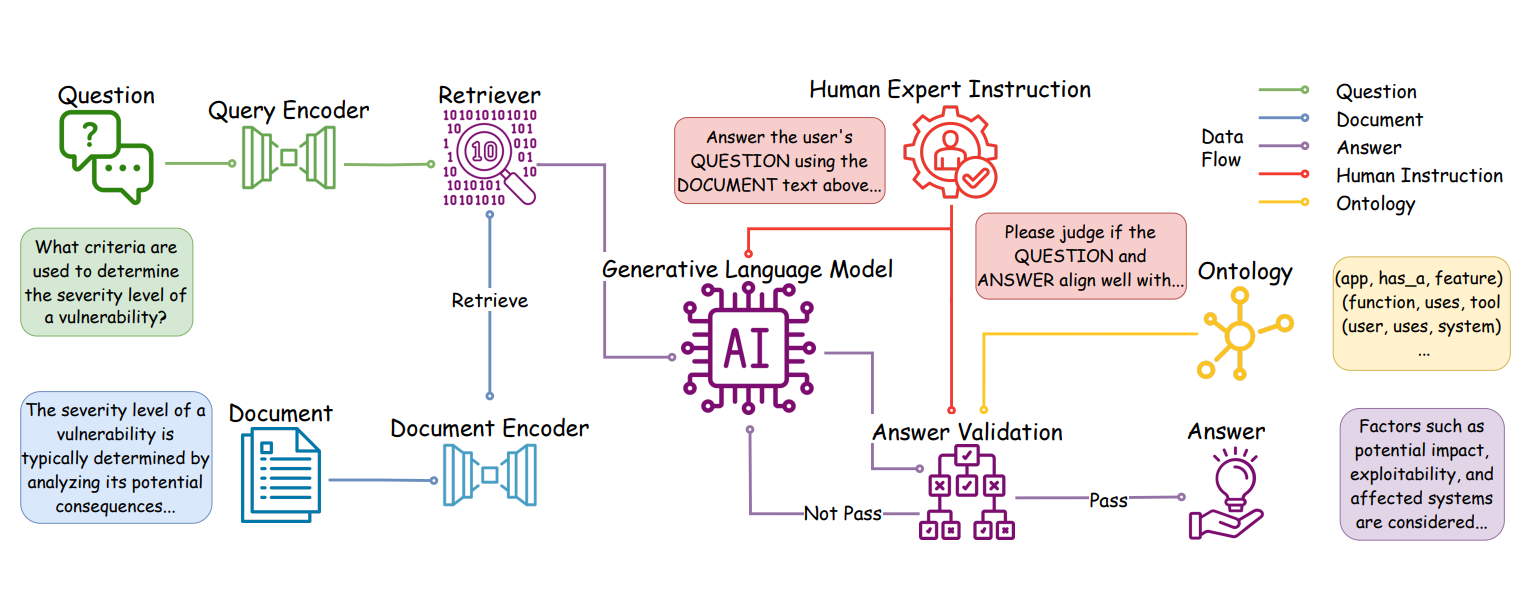 Ontology-aware rag for improved question-answering in cybersecurity educationChengshuai Zhao, Garima Agrawal, Tharindu Kumarage, and 4 more authorsarXiv preprint arXiv:2412.14191, 2024
Ontology-aware rag for improved question-answering in cybersecurity educationChengshuai Zhao, Garima Agrawal, Tharindu Kumarage, and 4 more authorsarXiv preprint arXiv:2412.14191, 2024Integrating AI into education has the potential to transform the teaching of science and technology courses, particularly in the field of cybersecurity. AI-driven question-answering (QA) systems can actively manage uncertainty in cybersecurity problem-solving, offering interactive, inquiry-based learning experiences. Large language models (LLMs) have gained prominence in AI-driven QA systems, offering advanced language understanding and user engagement. However, they face challenges like hallucinations and limited domain-specific knowledge, which reduce their reliability in educational settings. To address these challenges, we propose CyberRAG, an ontology-aware retrieval-augmented generation (RAG) approach for developing a reliable and safe QA system in cybersecurity education. CyberRAG employs a two-step approach: first, it augments the domain-specific knowledge by retrieving validated cybersecurity documents from a knowledge base to enhance the relevance and accuracy of the response. Second, it mitigates hallucinations and misuse by integrating a knowledge graph ontology to validate the final answer. Experiments on publicly available cybersecurity datasets show that CyberRAG delivers accurate, reliable responses aligned with domain knowledge, demonstrating the potential of AI tools to enhance education.
@article{zhao2024ontology, title = {Ontology-aware rag for improved question-answering in cybersecurity education}, author = {Zhao, Chengshuai and Agrawal, Garima and Kumarage, Tharindu and Tan, Zhen and Deng, Yuli and Chen, Ying-Chih and Liu, Huan}, journal = {arXiv preprint arXiv:2412.14191}, year = {2024}, }
2023
- ICLR
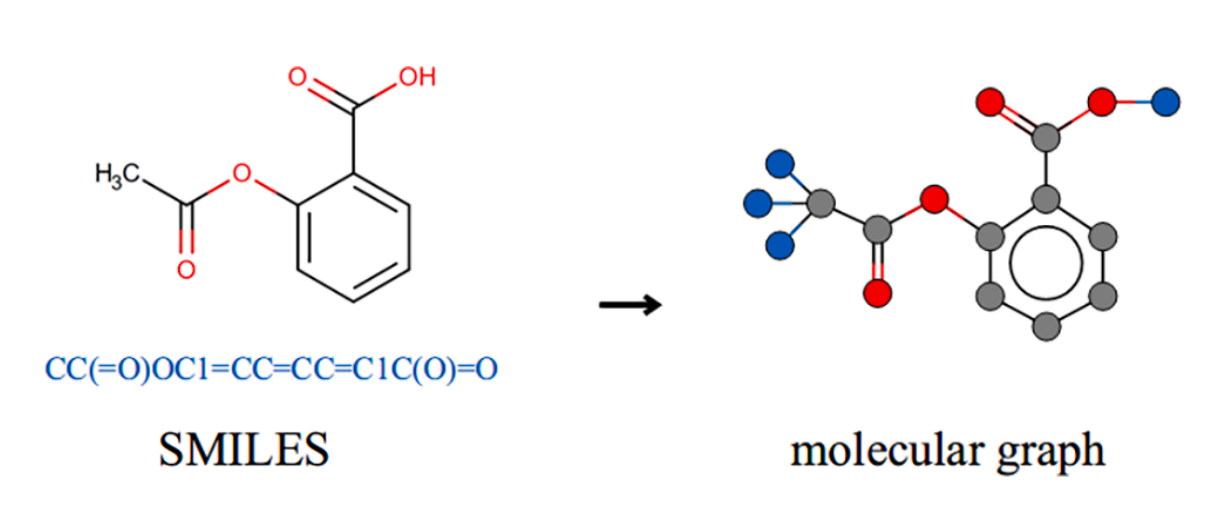
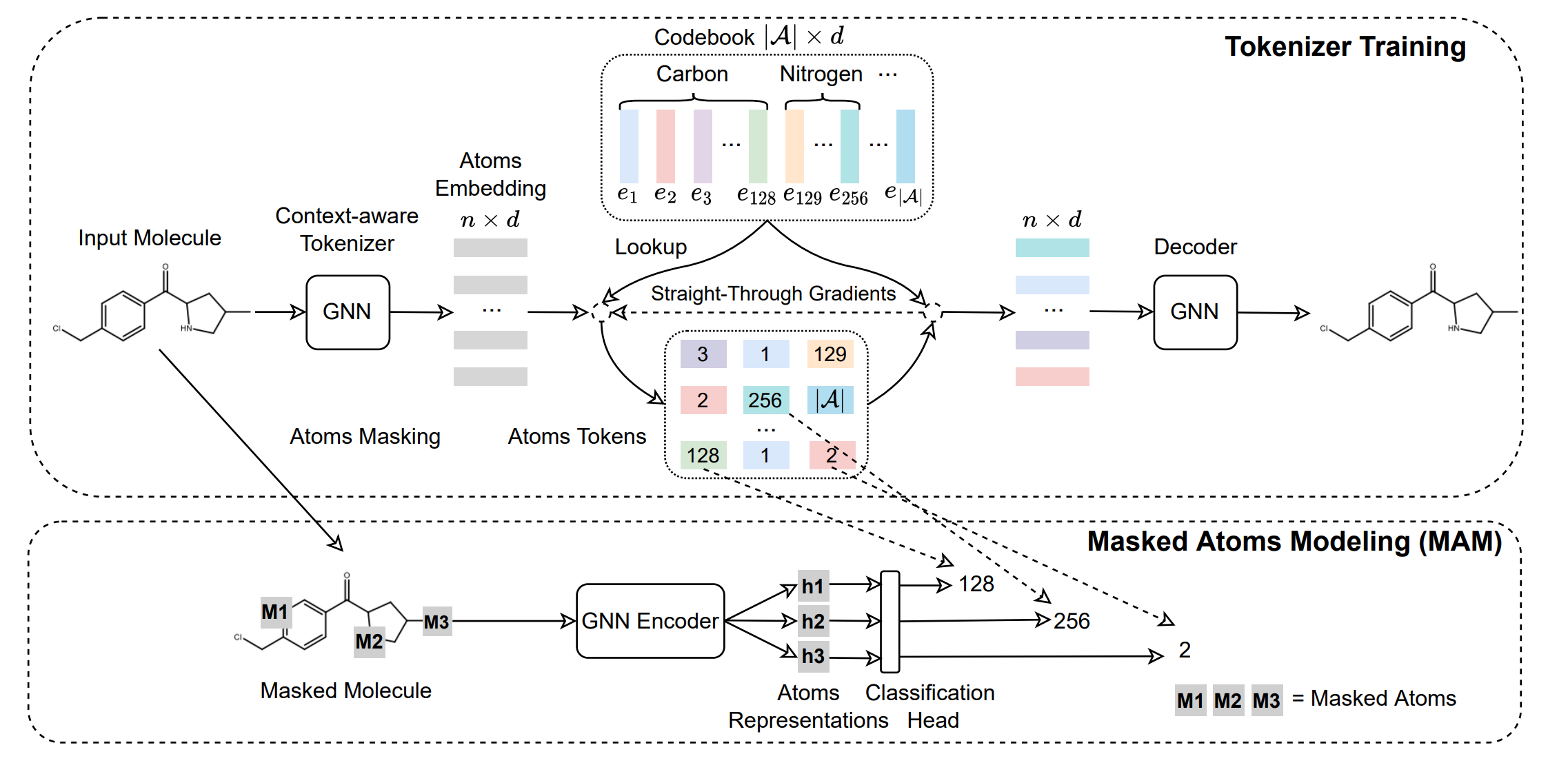 Mole-BERT: Rethinking Pre-training Graph Neural Networks for MoleculesJun Xia*, Chengshuai Zhao*, Bozhen Hu, and 5 more authorsIn The Eleventh International Conference on Learning Representations, 2023
Mole-BERT: Rethinking Pre-training Graph Neural Networks for MoleculesJun Xia*, Chengshuai Zhao*, Bozhen Hu, and 5 more authorsIn The Eleventh International Conference on Learning Representations, 2023This paper was accepted as a poster at ICLR 2023
Abstract: Recent years have witnessed the prosperity of pre-training graph neural networks (GNNs) for molecules. Typically, atom types as node attributes are randomly masked, and GNNs are then trained to predict masked types as in AttrMask, following the Masked Language Modeling (MLM) task of BERT. However, unlike MLM with a large vocabulary, the AttrMask pre-training does not learn informative molecular representations due to small and unbalanced atom vocabulary. To amend this problem, we propose a variant of VQ-VAE as a context-aware tokenizer to encode atom attributes into chemically meaningful discrete codes. This can enlarge the atom vocabulary size and mitigate the quantitative divergence between dominant (e.g., carbons) and rare atoms (e.g., phosphorus). With the enlarged atom vocabulary, we propose a novel node-level pre-training task, dubbed Masked Atoms Modeling (MAM), to mask some discrete codes randomly and then pre-train GNNs to predict them. MAM also mitigates another issue of AttrMask, namely the negative transfer. It can be easily combined with various pre-training tasks to improve their performance. Furthermore, we propose triplet masked contrastive learning (TMCL) for graph-level pre-training to model the heterogeneous semantic similarity between molecules for effective molecule retrieval. MAM and TMCL constitute a novel pre-training framework, Mole-BERT, which can match or outperform state-of-the-art methods in a fully data-driven manner.
@inproceedings{xia2023mole, title = {Mole-BERT: Rethinking Pre-training Graph Neural Networks for Molecules}, author = {Xia, Jun and Zhao, Chengshuai and Hu, Bozhen and Gao, Zhangyang and Tan, Cheng and Liu, Yue and Li, Siyuan and Li, Stan Z}, booktitle = {The Eleventh International Conference on Learning Representations}, year = {2023}, }
2022
- Journal
 Toward drug-miRNA resistance association prediction by positional encoding graph neural network and multi-channel neural networkChengshuai Zhao, Haorui Wang, Weiwei Qi, and 1 more authorMethods, 2022
Toward drug-miRNA resistance association prediction by positional encoding graph neural network and multi-channel neural networkChengshuai Zhao, Haorui Wang, Weiwei Qi, and 1 more authorMethods, 2022Drug discovery is a costly and time-consuming process, and most drugs exert therapeutic efficacy by targeting specific proteins. However, there are a large number of proteins that are not targeted by any drug. Recently, miRNA-based therapeutics are becoming increasingly important, since miRNA can regulate the expressions of specific genes and affect a variety of human diseases. Therefore, it is of great significance to study the associations between miRNAs and drugs to enable drug discovery and disease treatment. In this work, we propose a novel method named DMR-PEG, which facilitates drug-miRNA resistance association (DMRA) prediction by leveraging positional encoding graph neural network with layer attention (LAPEG) and multi-channel neural network (MNN). LAPEG considers both the potential information in the miRNA-drug resistance heterogeneous network and the specific characteristics of entities (i.e., drugs and miRNAs) to learn favorable representations of drugs and miRNAs. And MNN models various sophisticated relations and synthesizes the predictions from different perspectives effectively. In the comprehensive experiments, DMR-PEG achieves the area under the precision-recall curve (AUPR) score of 0.2793 and the area under the receiver-operating characteristic curve (AUC) score of 0.9475, which outperforms the most state-of-the-art methods. Further experimental results show that our proposed method has good robustness and stability. The ablation study demonstrates each component in DMR-PEG is essential for drug-miRNA drug resistance association prediction. And real-world case study presents that DMR-PEG is promising for DMRA inference.
@article{zhao2022toward, title = {Toward drug-miRNA resistance association prediction by positional encoding graph neural network and multi-channel neural network}, author = {Zhao, Chengshuai and Wang, Haorui and Qi, Weiwei and Liu, Shichao}, journal = {Methods}, volume = {207}, pages = {81--89}, year = {2022}, publisher = {Elsevier}, }
2021
- Journal
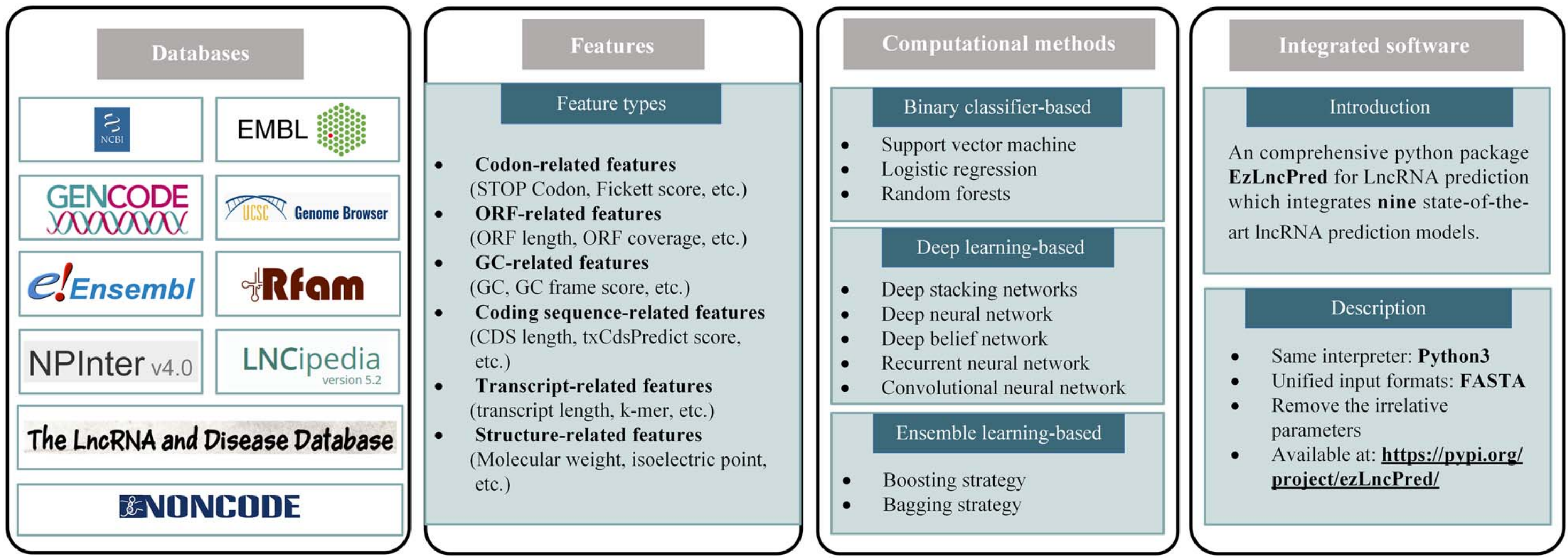 A systematic review of computational methods for predicting long noncoding RNAsXinran Xu, Shuai Liu, Zhihao Yang, and 6 more authorsBriefings in Functional Genomics, 2021
A systematic review of computational methods for predicting long noncoding RNAsXinran Xu, Shuai Liu, Zhihao Yang, and 6 more authorsBriefings in Functional Genomics, 2021Accurately and rapidly distinguishing long noncoding RNAs (lncRNAs) from transcripts is prerequisite for exploring their biological functions. In recent years, many computational methods have been developed to predict lncRNAs from transcripts, but there is no systematic review on these computational methods. In this review, we introduce databases and features involved in the development of computational prediction models, and subsequently summarize existing state-of-the-art computational methods, including methods based on binary classifiers, deep learning and ensemble learning. However, a user-friendly way of employing existing state-of-the-art computational methods is in demand. Therefore, we develop a Python package ezLncPred, which provides a pragmatic command line implementation to utilize nine state-of-the-art lncRNA prediction methods. Finally, we discuss challenges of lncRNA prediction and future directions.
@article{xu2021systematic, title = {A systematic review of computational methods for predicting long noncoding RNAs}, author = {Xu, Xinran and Liu, Shuai and Yang, Zhihao and Zhao, Xiaohan and Deng, Yaozhen and Zhang, Guangzhan and Pang, Jian and Zhao, Chengshuai and Zhang, Wen}, journal = {Briefings in Functional Genomics}, volume = {20}, number = {3}, pages = {162--173}, year = {2021}, publisher = {Oxford University Press}, } - IJCAI
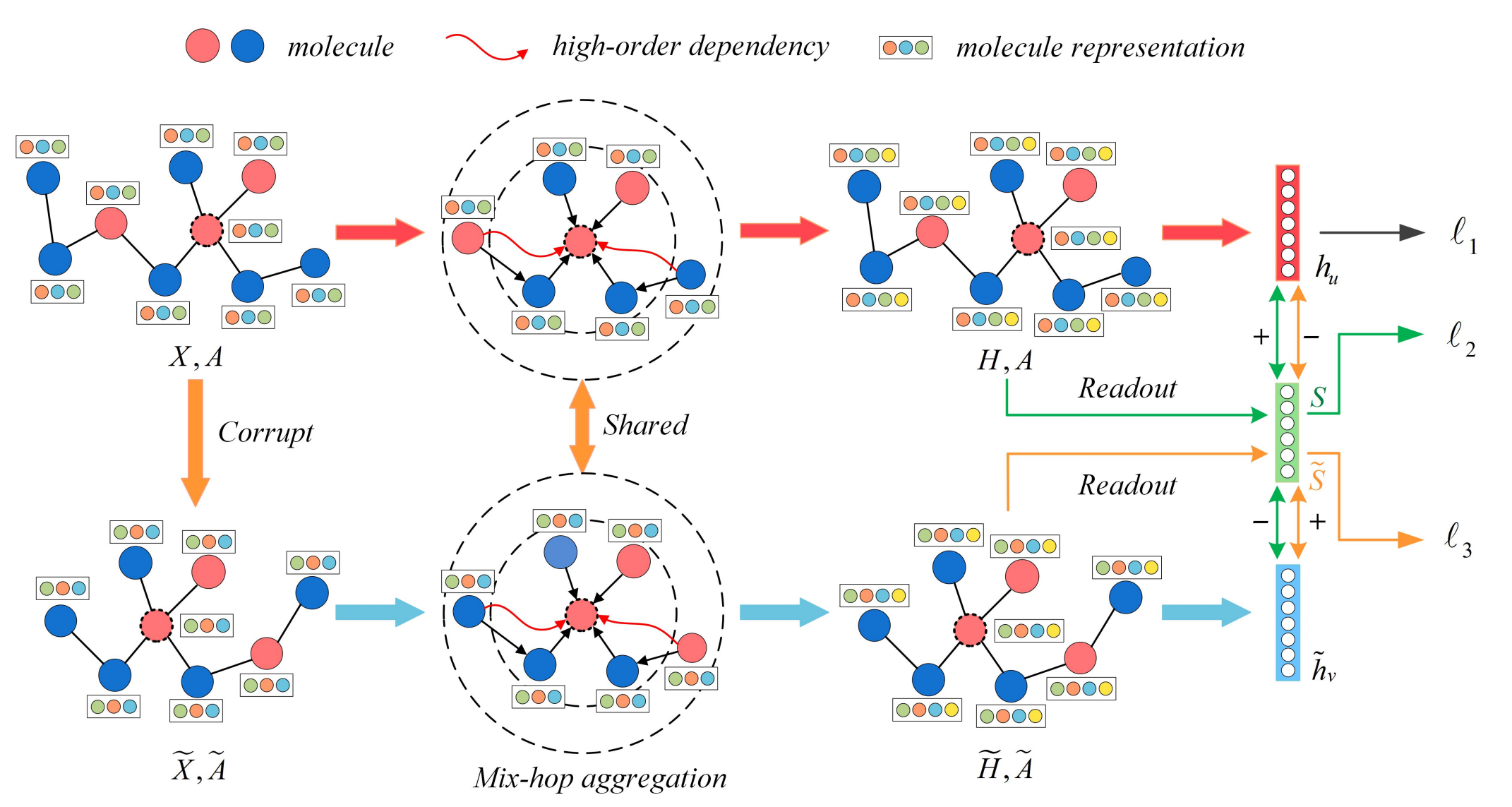 CSGNN: Contrastive Self-Supervised Graph Neural Network for Molecular Interaction Prediction.Chengshuai Zhao, Shuai Liu, Feng Huang, and 2 more authorsIn Proceedings of the Thirtieth International Joint Conference on Artificial Intelligence, 2021
CSGNN: Contrastive Self-Supervised Graph Neural Network for Molecular Interaction Prediction.Chengshuai Zhao, Shuai Liu, Feng Huang, and 2 more authorsIn Proceedings of the Thirtieth International Joint Conference on Artificial Intelligence, 2021Molecular interactions are significant resources for analyzing sophisticated biological systems. Identification of multifarious molecular interactions attracts increasing attention in biomedicine, bioinformatics, and human healthcare communities. Recently, a plethora of methods have been proposed to reveal molecular interactions in one specific domain. However, existing methods heavily rely on features or structures involving molecules, which limits the capacity of transferring the models to other tasks. Therefore, generalized models for the multifarious molecular interaction prediction (MIP) are in demand. In this paper, we propose a contrastive self-supervised graph neural network (CSGNN) to predict molecular interactions. CSGNN injects a mix-hop neighborhood aggregator into a graph neural network (GNN) to capture high-order dependency in the molecular interaction networks and leverages a contrastive self-supervised learning task as a regularizer within a multi-task learning paradigm to enhance the generalization ability. Experiments on seven molecular interaction networks show that CSGNN outperforms classic and state-of-the-art models. Comprehensive experiments indicate that the mix-hop aggregator and the self-supervised regularizer can effectively facilitate the link inference in multifarious molecular networks.
@inproceedings{zhao2021csgnn, title = {CSGNN: Contrastive Self-Supervised Graph Neural Network for Molecular Interaction Prediction.}, author = {Zhao, Chengshuai and Liu, Shuai and Huang, Feng and Liu, Shichao and Zhang, Wen}, booktitle = {Proceedings of the Thirtieth International Joint Conference on Artificial Intelligence}, publisher = {International Joint Conferences on Artificial Intelligence Organization}, pages = {3756--3763}, year = {2021}, }
2020
- Journal
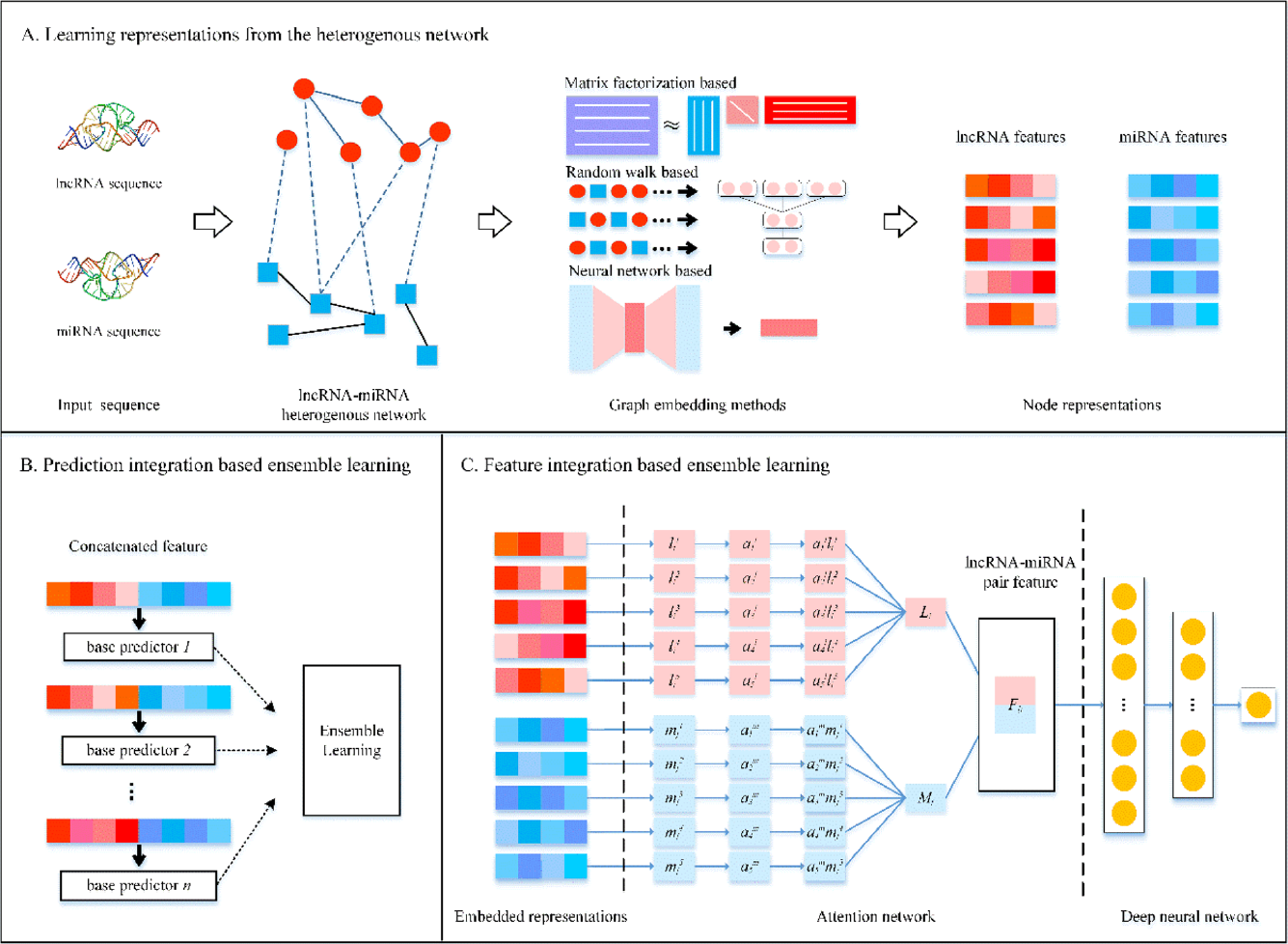 Graph embedding ensemble methods based on the heterogeneous network for lncRNA-miRNA interaction predictionChengshuai Zhao, Yang Qiu, Shuang Zhou, and 3 more authorsBMC genomics, 2020
Graph embedding ensemble methods based on the heterogeneous network for lncRNA-miRNA interaction predictionChengshuai Zhao, Yang Qiu, Shuang Zhou, and 3 more authorsBMC genomics, 2020Researchers discover LncRNA-miRNA regulatory paradigms modulate gene expression patterns and drive major cellular processes. Identification of lncRNA-miRNA interactions (LMIs) is critical to reveal the mechanism of biological processes and complicated diseases. Because conventional wet experiments are time-consuming, labor-intensive and costly, a few computational methods have been proposed to expedite the identification of lncRNA-miRNA interactions. However, little attention has been paid to fully exploit the structural and topological information of the lncRNA-miRNA interaction network. In this paper, we propose novel lncRNA-miRNA prediction methods by using graph embedding and ensemble learning. First, we calculate lncRNA-lncRNA sequence similarity and miRNA-miRNA sequence similarity, and then we combine them with the known lncRNA-miRNA interactions to construct a heterogeneous network. Second, we adopt several graph embedding methods to learn embedded representations of lncRNAs and miRNAs from the heterogeneous network, and construct the ensemble models using two ensemble strategies. For the former, we consider individual graph embedding based models as base predictors and integrate their predictions, and develop a method, named GEEL-PI. For the latter, we construct a deep attention neural network (DANN) to integrate various graph embeddings, and present an ensemble method, named GEEL-FI. The experimental results demonstrate both GEEL-PI and GEEL-FI outperform other state-of-the-art methods. The effectiveness of two ensemble strategies is validated by further experiments. Moreover, the case studies show that GEEL-PI and GEEL-FI can find novel lncRNA-miRNA associations. The study reveals that graph embedding and ensemble learning based method is efficient for integrating heterogeneous information derived from lncRNA-miRNA interaction network and can achieve better performance on LMI prediction task. In conclusion, GEEL-PI and GEEL-FI are promising for lncRNA-miRNA interaction prediction.
@article{zhao2020graph, title = {Graph embedding ensemble methods based on the heterogeneous network for lncRNA-miRNA interaction prediction}, author = {Zhao, Chengshuai and Qiu, Yang and Zhou, Shuang and Liu, Shichao and Zhang, Wen and Niu, Yanqing}, journal = {BMC genomics}, volume = {21}, number = {13}, pages = {1--12}, year = {2020}, publisher = {BioMed Central}, }